2019 In Summarization Research
Background
This article aims to provide an overview of the summarization research in 2019. The NLP community has done a great job of organizing publications across venues in a common repository, the ACL Anthology. For my analysis, I pulled out the consolidated bibtex files for ACL, NAACL and EMNLP conferences from 2019. These are the top-tier NLP conferences, as confirmed by a quick lookup on Google scholar.
I then used the python bibtexparser library to parse the bib files and used some simple keyword matching to get to the summarization papers. This returned 58 papers, which I then skimmed over and did a hybrid top-down and bottom-up clustering to organize them into a loose topical hierarchy. Let’s dive into the results.
Focus of Summarization Community
How big is the summarization community compared to the rest of NLP? The table below show that 2-4% of the papers at the top 3 NLP venues were on summarization. These numbers are similar to 2018 numbers and are also similar to other areas such as question answering and sentiment analysis.
| # All papers | # Summarization papers | % Summarization | |
|---|---|---|---|
| EMNLP | 681 | 23 | 3% |
| NAACL | 423 | 8 | 2% |
| ACL | 660 | 27 | 4% |
| Total | 1764 | 58 | 3% |
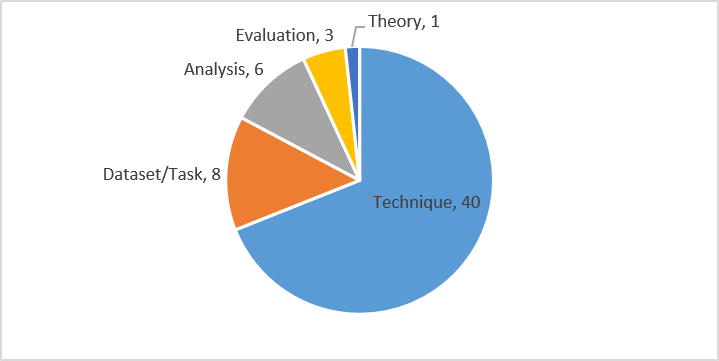
The figure below shows the distribution of summarization papers across some high-level themes. 40 papers, 69% of the total, were focused on introducing new techniques for summarization. The next biggest focus area was papers introducing new datasets and new tasks (8 papers). There were a number of analysis papers as well (6 papers), many offering critical evaluation of current summarization datasets and evaluation metrics. Finally, there were 3 papers introducing new evaluation techniques (5%) and one theory paper.
Let’s now look into the details of each of those clusters, starting from the biggest one: Techniques.
New Techniques
There was a lot of diversity in summarization techniques explored by the research community in 2019, but I see some clear themes. In the text below, I’ve skipped the year from the citations of the 2019 papers and have included a link to the paper PDFs in ACL Anthology.
Reinforcement Learning Rewards
There were four papers focusing on reinforcement learning (RL) based summarization methods, all of them focusing on designing better rewards. Previous RL systems have used ROUGE as the reward for their RL systems, but new works criticize ROUGE as a reward and propose new reward metrics. For example, Bohm et al. learned a reward function from human rating on 2500 summaries and use it for training the RL systems. Scialom et al. and Arumae & Liu proposed question answering based reward metrics that work better than ROUGE. Li et al. propose a BERT based similarity score for rewards instead of ROUGE that works on n-gram overlap (this move towards distributional similarity from n-gram overlap appears in the evaluation papers as well).
Transformer Based Approaches
Not surprisingly, a number of BERT and other transformer based approaches have appeared. Zhang et al. introduce HIBERT, a technique that extends the original BERT objective by predicting masked sentences instead of masked words. Liu & Lapata introduce BERTSum, a simple but effective technique that runs inference on all sentences of a document together using a joint transformer architecture. Another interesting paper was Liu & Lapata, which used hierarchical transformers for multi-document summarization on the WikiSum dataset.
Using Latent Discourse Structure
In this section, I am grouping several papers that try to use latent discourse structure of input text.
Templates: In old-school summarization, template based generation was a popular technique. There seems to be a new interest in learning templates automatically from data and using them to guide summaries. Gao et al. use labeled document-summary pairs to obtain summary patterns and prototype facts, which are then used to guide the generated summary. Wang et al. also propose a method to extract template summaries from training data that are then used as an additional input for the summarizer.
Topical structure: A different direction is to uncover the latent topical structure of the input documents and use it to guide summaries. Zheng et al. present an RNN based model that learns subtopics and uses them to build an extractive summary for news articles. Perez-Beltrachini et al. extract LDA topics and train their document-level decoder to predict sentence topics as an auxiliary task. This is a direction I find really promising. Back in the day, a number of good summarization models were based on uncovering topical structure, e.g. Barzilay & Lee 2004 and Haghighi & Vanderwende 2009. I explored this area during my PhD as well (Jha et al. 2015).
Entity distribution: Modeling distribution of entities is a great way to capture the discourse structure of text. Sharma et al. use an entity-driven hybrid summarization model that first uses an entity-aware content selection module to select sentences, followed by an abstractive component. Again, this work renews an older thread of research around modeling entities in discourse, e.g. Barzilay & Lapata 2008.
Discourse parsing: This direction is not as popular now as it used to be, but Liu & Lapata are trying to bring it back in fashion by inducing multi-root dependency trees relating sentences to each other and using them for summarization. These dependency trees are a loose version of the rigid RST based discourse trees people have tried before (e.g. Marcu99).
Unsupervised Summarization
Last year also saw a number of new unsupervised techniques, I’ll mention two. Zheng & Lapata revisit network centrality for summarization by using BERT based representations for capturing similarities and using directed graphs based on document position. Network based methods are one of the all-time most successful methods for summarization (e.g. Erkan & Radev’s Lexrank has more than 2000 citations). West & Choi present an interesting technique called BottleSum that tries to summarize a sentence by learning to keep only the information that is needed to predict the next sentence.
Tweaking previous methods
A number of papers tried to improve previous architectures by tweaking attention in various ways: You et al. tried a new focus-attention mechanism, Gui et al. tried an attention refinement unit paired with local variance loss and Duan et al. tried contrastive attention. Two papers tried to improve Pointer-Generator networks: Shen et al. allow their pointers to edit pointed tokens and Wenbo et al. add a concept pointer to incorporate external knowledge.
Analysis Papers
Kryscinski et al. did a critical evaluation of neural text summarization and highlighted three shortcomings: 1) automatically collected datasets leave the task under constrained and may contain noise, 2) current evaluation protocol is weakly correlated with human judgment 3) models overfit to layout biases of current datasets. The concern around the unconstrained nature of the summarization task resonates with me, it makes evaluation very tricky. In another critical evaluation, Peyrad claims that evaluation metrics like ROUGE strongly disagree in the higher scoring range in which the current systems operate.
Jung et al. evaluate the bias in several summarization datasets on the aspects of position, importance and diversity. Not surprisingly, news datasets show high bias for position, but this is not true for academic papers and meeting minutes. There is a lot of useful information in this paper that should guide researchers in their data annotation efforts. In a related work, Zhong et al. analyze the impact of different components in extractive neural summarization models.
New Evaluation Techniques and Datasets
Sun & Nenkova present a great set of experiments on using distributed representations for summarization evaluation compared to n-gram overlap in ROUGE. Eyal et al. use the progress in Question Answering (QA) to design an evaluation based on automated QA systems called APES (Answering Performance for Evaluation of Summaries). The idea is that a good summary should allow a QA system to answer salient questions related to the original text. Hardy et al. present a new methodology for human evaluation in which summaries are assessed by multiple annotators via manually highlighted salient content in the source document.
I found three of the new datasets interesting. Sharma et al. introduce BigPatent, a dataset of 1.3 million abstractive patent summaries. Lev et al. introduce TalkSumm, a dataset for scientific paper summarization created by aligning papers and their conference talk transcripts. Fabri et al. created one of the few large scale multi-document news summarization datasets called Multi-News with about 56,000 examples.
Finally, Deutsch & Roth introduce an interesting new task called summary cloze: to generate the next sentence of a summary conditioned on the beginning of the summary, a topic, and a reference document. They release a dataset of 500,000 summary cloze instances based on Wikipedia.
Final Thoughts
Clearly, the summarization community is active as ever! I hope you found this review useful. If you’re interested in exploring this more, I’ve uploaded the raw text file with all the papers organized into my topic hierarchy here.