How Language Models Took Over NLP
Language modelling used to be a sub-area within NLP 1, but over the past decade, language models have taken over NLP and seem poised to take over many other areas of AI. In this article, I want to trace the evolution of language models from the 80’s, when they were estimated using traditional count-based methods and used for a small number of NLP applications, to today where large language models are being used as general purpose AI engines for numerous applications, even beyond NLP.
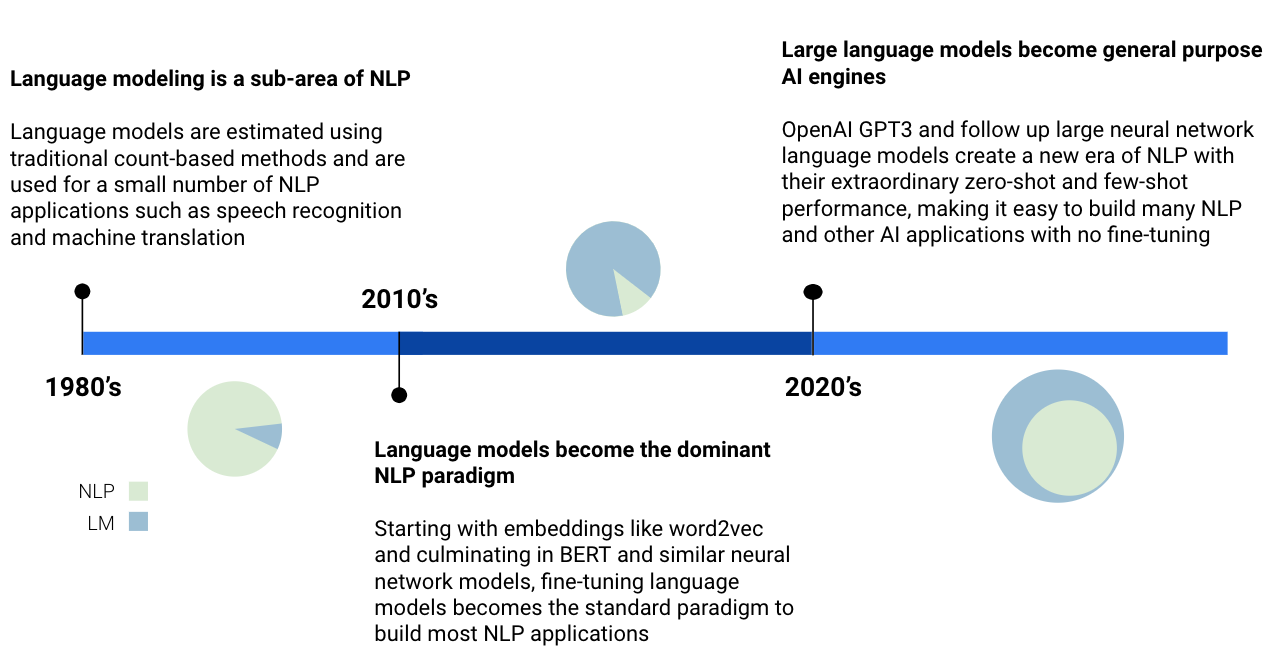
1980’s and 1990’s: Language modeling as a sub-area
At its most fundamental, a language model is used to determine the probability of a word sequence $[w_1, w_2, … w_n]$. The probability depends on the usage for the language in question. For example, the probability of a common word sequence in English like [my, name, is] should be much higher than the probability of a less common word sequence like [is,cheese, name] in a reasonable language model 2.
If we use $P(w_1…w_n)$ to denote this probability, it can be broken down like this:
\[P(w_1...w_i) = P(w_1) \times P(w_2 \mid w_1) \times ... \times P(w_i \mid w_1 ... w_{i-1})\]Here $P(w_i \mid w_1…w_{i-1})$ is the conditional probability of observing $w_i$ given that you observed word sequence $[w_1…w_{i-1}]$ before. Since this probability can get difficult to compute for long sequences, old-style language modeling often made the simplifying assumption that the probability of a word depends only on the previous few words. So, for example, a trigram model would assume that the probability of a word depends on only the previous two words, so you just need to estimate $P(w_i \mid w_{i-2}w_{i-1})$.
These probabilities can be estimated simply by counting the occurrences of word sequences in your data. For example, if you wanted to estimate the probability $P(my, name, is \mid my, name)$, you count the number of times you saw the words [my, name, is] (say 30,000 times) and the number of times you saw the words [my, name] (say 40,000). Then your probability would be:
This can be noisy because of the limitations of the dataset, for example, some sequences may never occur. Many techniques were developed to learn better language models, such as smoothing and clustering. (Goodman, 2008) provides a great overview of the work done in this era of language modeling. These early language models were a component for several NLP tasks such as speech recognition and machine translation.
All these approaches depended on using words as discrete tokens. One problem with this approach is that you can’t generalize to a new sequence of words even if you have seen a sequence of similar words. For example, if you have seen the sequence [Tomorrow, is, Monday] in your data, you should be able to assign a higher probability to [Tomorrow, is, Tuesday], since Monday and Tuesday are similar words. But a purely token based approach like we discussed above can’t do that. Trying to solve this problem in a systematic manner led to the first big step in making language modeling a cornerstone for many NLP tasks.
2010’s: Language models become the dominant NLP paradigm
So how do you learn about sequences of words that never appear together in your dataset? Think about how you process language for a minute. When you see a sequence like [My, calendar, is, fully, booked, on, Monday], even if this is the first time you’re seeing this sentence, you know that any day of the week can appear instead of Monday. That’s because you know words like Monday and Tuesday are related.
Bengio et al. 2003 proposed a clever solution that blew my mind the first time I read it during my PhD. The idea is to create a distributed representation of words by representing each word by a feature vector. Instead of learning probabilities of sequences of tokens, you now learn probabilities of sequences of these feature vectors.
How does it work? Let’s say you use feature vectors of length 2 for representing your words. Consider you assigned these feature vectors.
| Word | Feature Vector |
|---|---|
Tomorrow |
[0.2, 0.8] |
is |
[0.9, 0.3] |
Monday |
[0.4, 0.5] |
Tuesday |
[0.5, 0.4] |
Now, when there is a sequence like [Tomorrow, is, Monday] in your training data, your language model instead sees the sequence [[0.2, 0.8], [0.9, 0.3], [0.4, 0.5]] and learns to assign it a high probability. The next time you ask the model about [Tomorrow, is, Tuesday], even though the model may not have seen this exact sequence of words, it can assign a higher probability to it because the vectors for Monday and Tuesday are so close together.
The paper that really demonstrated the power of these distributed representations is my all time favorite paper: NLP from scratch (Collobert et al., 2011). This paper was the first paper that built a unified neural network architecture for many NLP tasks and demonstrated that learning unsupervised distributed representations of words can improve performance across many tasks 3.
This paper led to an explosion of work in learning distributed representations (by now called word embeddings) such as Word2Vec and Glove. They were shown to improve performance in many scenarios, and people quickly adapted their NLP pipelines to leverage word embeddings. By 2015, I saw this really funny tweet when walking around in EMNLP. But it was also true, the era of language models had arrived.
 |
|---|
Over the next several years, language models kept getting bigger and better. The main trends were contextual representations and the pre-train and fine-tune paradigm, as exemplified by Elmo, BERT and GPT architectures. This progress has been covered a lot elsewhere, so I’ll not go into the details here. In summary, the dominant NLP paradigm by 2020 was the pre-train and fine-tune paradigm. You pretrained a large model using a language modeling objective on a large amount of unlabeled data. Then for a new task, you added a small layer on the top and fine-tuned the model using task-specific labeled data. 4
2020’s: Language models take over NLP …
One of the important models that came in the previous era was OpenAI’s GPT (Radford et al. 2018) architecture. This was a decoder-only model, which just means that it was trained to generate text in a left-to-right fashion, similar to the language models we saw in the first section. Given an input sequence, GPT would predict the next token in the sequence. Scaling this simple architecture to larger sizes started to show some surprising results.
The next iteration of GPT, with the uninspiring name of GPT2 (Radford et al., 2019) showed some interesting results about how the language model could do tasks it was never trained for, like machine translation and summarization. The authors hypothesized that this was because even unlabeled contained natural demonstrations for many tasks. For example, the figure below taken from the paper shows examples of English to French and back translations occurring naturally in data.
 |
|---|
| Figure from GPT2 paper showing naturally occuring demonstrations for English to French machine translation |
This was a tantalizing idea. It meant that you didn’t need to train separate models for many NLP tasks, but could just rely on a language modeling architecture trained on large amounts of unlabeled data. Another paper from this time presented the T5 (Raffel et al. 2020) architecture. They developed a framework where all NLP problems are represented as a text-to-text problem, that is, taking text as an input and text as an output. The figure below from the paper shows how it worked. To translate from English to German, you just give the model the instruction, followed by the sentence to translate, and it spits out the answer, token-by-token.
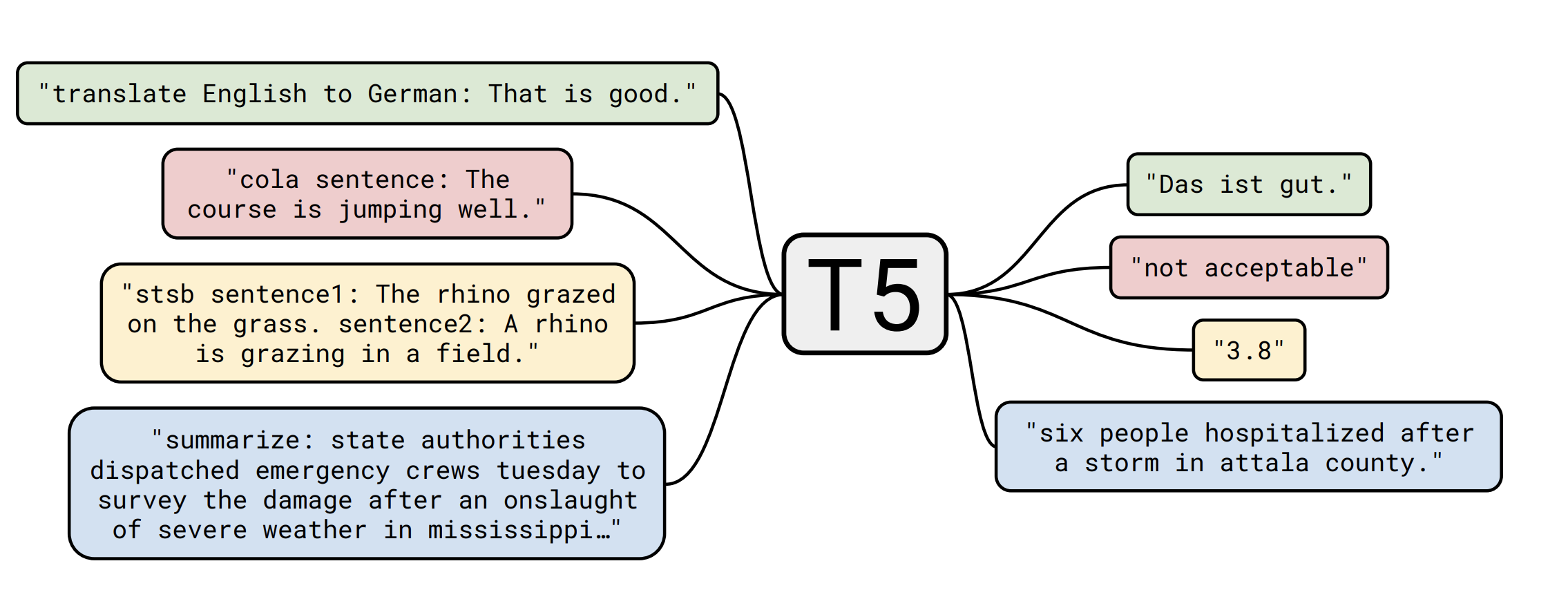 |
|---|
| The T5 framework where all tasks are represented in a text-to-text framework. |
These models really showed that a large language model trained on a huge amount of carefully prepared unlabeled data could be a general NLP system. But we hadn’t the end of this line of research. The GPT3 paper (Brown et al. 2020) demonstrated that a sufficiently large language model could even be made to do completely new tasks with just general instructions and only a few examples. You can see some of the examples from the paper in the figure below. The interesting thing here is that you’re not doing any additional fine-tuning on the language model at all. You just give the task description, along with the examples, as an input to the language model, and ask it to complete the text.
 |
|---|
| Examples of zero-shot, one-shot and few-shot methods of performing a task with GPT3 |
GPT3 was really powerful, but it was still tricky to figure out exactly what text input to use to get the best results for a task. People started looking into “prompt engineering”, or the best way to convert your input into a prompt to get the best results on a task. The model was really capable, but it was sometimes hard to get it to do exactly what you needed it to do.
InstructGPT presented RLHF (Reinforcement Learning with Human Feedback) as a solution to this problem. RLHF has been explained really well in this article, I won’t go over the details here. Essentially, it uses a Reinforcement Learning setup to “align” the language model so it can better understand what it is being asked to do. A really large language model with instruction fine-tuning using RLHF is the recipe behind the recent success of large language models like chatGPT.
… and go beyond
The recent large language models are really impressive. Playing around with GPT4, I am amazed at how well it responds to complex instructions, and the range of things it’s able to do well. It really feels like we could replace all of NLP with these large language models. And it’s going beyond NLP, e.g. see this ICML paper that uses large language models for planning, a classic AI task. This paper explores large language models for many use cases beyond NLP in the domains of mathematics, coding, vision, medicine and more.
An exciting recent development is the emergence of a lot of open-source large language models that have started to compete with the proprietary language models from openAI and others. This should allow us to make faster progress towards the next generation of language models. I am excited to see the applications we’ll dream of.
Footnotes
-
NLP or Natural Language Processing is the sub-field of AI devoted to building and understanding systems involving human language. ↩
-
When I had used this example in a talk, one of my colleagues felt compelled to send me this passage: “Is cheese name an important factor? Typically, the flavor profile is given more weight when deciding among several cheeses, but it can also be important to select cheese whose names are easily pronounceable – especially if you’re planning to use your cheese board as “smalltalk fodder” ↩
-
I was in the second year of my PhD and implemented parts of this paper in Lua torch (This is pre Tensorflow/PyTorch). Given the number of requests I got for the code, I think this was the only implementation available for a while (code, presentation). ↩
-
A big reason for all this progress was the Transformer architecture, which allowed training such big language models in the first place. See this excellent article for an introduction. ↩