NAACL 2018 Summary
NAACL is one of the top conferences in the area of Natural Language Processing (NLP). This year, NAACL was held in New Orleans, Louisiana. I attended the main conference this year and it was a pretty well-run event! I learnt a lot, here are some of my notes.
Transfer Learning
Deep learning continued to dominate machine learning techniques for NLP at NAACL 2018. Transfer learning and mutli-task learning methods got a lot attention both in research and industry track.
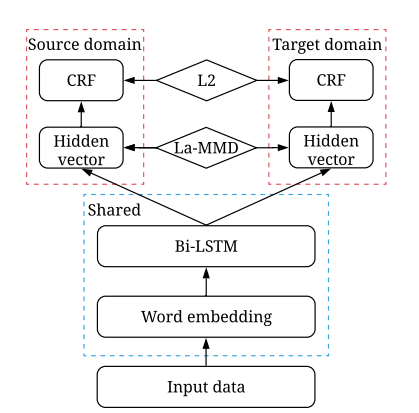 Wang et al. presented a transfer learning technique for NER on medical records. The main idea behind their architecture is to share parameters in the initial embedding and LSTM layers, and reduce the feature representation discrepancy in the higher layers by using maximum mean discrepancy (MMD).
Wang et al. presented a transfer learning technique for NER on medical records. The main idea behind their architecture is to share parameters in the initial embedding and LSTM layers, and reduce the feature representation discrepancy in the higher layers by using maximum mean discrepancy (MMD).
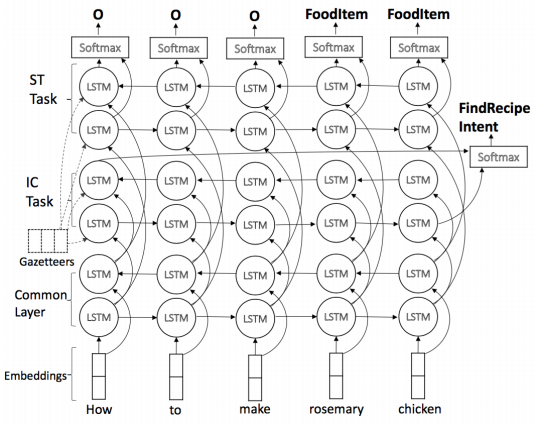
Goyal et al. presented an architecture for joint training of intents and slot tagging for conversational understanding applications. Their transfer learning approach is based on pre-training the network using source domain, and then fine-tuning the top-most affine transform and softmax layers using target domain. They showed good improvements over 200 domains using their transfer learning approach. An interesting, though not surprising, result was that the largest gains from transfer learning were seen for the most low resource data settings. We saw similar results in our experiments with Bag of Experts transfer learning paper for NAACL 2018 (Jha et al.)
Shah et al. presented an approach for training end-to-end neural models for conversational agents by using dialogue self-play between a simulated user and a task-independent programmed system agent to generate initial template utterances, which are then paraphrased further through crowdsourcing.
Another interesting paper was Chen et al., where they propose to use multinomial adversarial networks for the task of multi-domain text classification (MDTC), which they describe as a more general version of domain adaptation where instead of one source and target domain, you have multiple domains with some domains suffering from the problem of limited or no labeled data.
Augenstein et al. presented an interesting approach around combining multi-task learning with semi-supervised learning by using a Label Embedding Layer to model the relationships between labels for similar tasks (e.g. POS tagging and dependencies), and training a Label Transfer Network (LTN) to transfer labels between tasks.
Conversational Modeling
Conversational modeling for task-oriented systems also got a lot of attention from the community. An interesting paper was the Alexa Meaning Representation Language: Kollar et al.. They did not present any results, but introduced Alexa’s large hierarchical ontology with types, properties, actions and roles. The AMRL is a “graph-based domain and language independent meaning representation that can capture the meaning of spoken language utterances to intelligent assistants.” There is a lot of good motivation for moving towards a better representation from the flat domain/intent/slot schema, but it does introduce challenges in terms of modeling. As far as I understood, the AMRL is reduced to a flat representation when building models today so that standard modelling techniques would work.
In other papers, Su et al. proposed a time-decay attention mechanism for modeling contextual history in dialogue. Suhr et al. also experimented with various architectures for modeling context in conversations. (Code available here).
Park et al. presented an approach for alleviating the degeneration problem that comes up in using variational autoencoders with hierarchical RNN’s for conversational modeling. One interesting problem in modeling human-to-human conversations is to disentagle interleaved threads in chat systems like the IRC. Jiang et al. presented an architecture for this using Siamese Hierarchical Networks and similarity ranking.
Adversarial Training
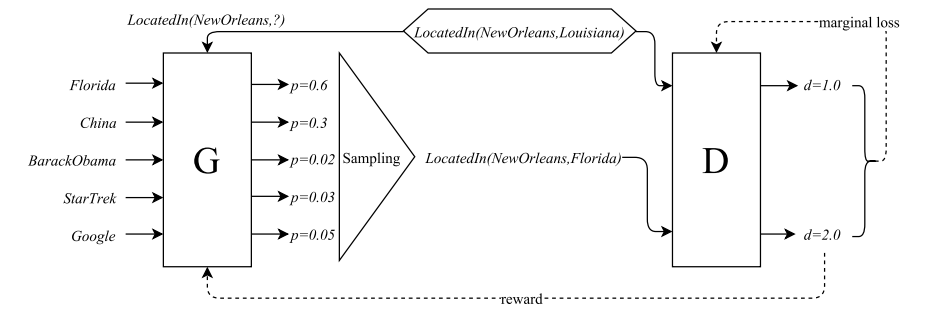
A number of papers attempted to use adversarial learning for learning robust representations for NLP tasks. Cai et al. had a very nice talk about their adversarial learning framework for improving performance of knowledge graph embedding models. Li et al. presented an approach for using adversarial training for learning domain-robust text representations in multitask learning scenarios. Wang et al. proposed an adversary-generation algorithm for increasing the robustness of Question Answering models, and showed that it outperforms other models in different types of adversarial evaluation.
Others
Peters et al. gave a fantastic talk about ELMo (and won the best paper award!). ELMo generates word representations that models both syntax/semantics as well as word usage across linguistic contexts. Several people have told me they’ve seen good improvements using ELMo, so the award is definitely well-deserved. They have a lot of resources on their web page. Chen et al. had a nice paper that investigates Recurrent Neural Networks as Weighted Language Recognizers (also nominated for best-paper).
Final notes
There was a wonderful Test of Time session with three papers from around 2002 that have had significant impact on the community. Kishore Papineni, Michael Collins and Bo Pang gave beautiful (and funny!) talks looking back at the impact their work has had over the years. I hope the videos for these will be made available. For me, the talks did a good job of summing up the spirit of the ACL community.